Introduction
This article describes a very specific use case of MongoDB, where we want to query for documents belonging to certain categories, and get the most recent n documents first.
The two key conditions are therefore
-
Categories
This means that your documents belong to one of a set of distinct values. Imagine news articles that can belong to a category like “Politics”, “Technology”, “Sports”, etc. In this example we won’t consider documents with multiple categories (tags), but thanks to MongoDB’s multi-key indexes, the same principles can be extended to those cases as well.
var result = db.documents .find({category: {"$in": ["Business", "Politics", "Sports"]}}) -
Recency
We are interested in “the most recent” n documents. This implies some sorting order, ensured by an index on a timestamp-like field (ts) and traditionally a sort and limit on the result set:
var n = 10000; var result = db.documents .find({category: {"$in": ["Business", "Politics", "Sports"]}}) .sort({ts:-1}) .limit(n)
I say “traditionally”, because sorting is often used for this kind of problem, and while that certainly guarantees the most recent n documents, this may not be the optimal solution for the problem. It really depends what happens to these documents next. If they need to be processed or presented in an ordered list, then yes, this is really the only solution. It is, however, a stronger requirement than the one we stated in the beginning. There is a significant difference between “most recent n” and “most recent n in sorted order”. One that we’re going to exploit in this article. Perhaps my task is to batch-process a queue of jobs. I can process 1,000 jobs simultaneously, and the relative order of the jobs doesn’t matter, as long as I get the most recent 1,000 jobs in the queue.
What are the options?
Let’s have a look at how this particular problem can be addressed in MongoDB. For any kind of efficient document retrieval, we need to define an index on the fields in question. But in what order should the fields be arranged?
Index on {category:1, ts:-1}
This index first branches into the categories, then sorts the documents on their timestamp, in descending order. This seems like a good match, as we could quickly determine the documents matching the categories (our first condition).
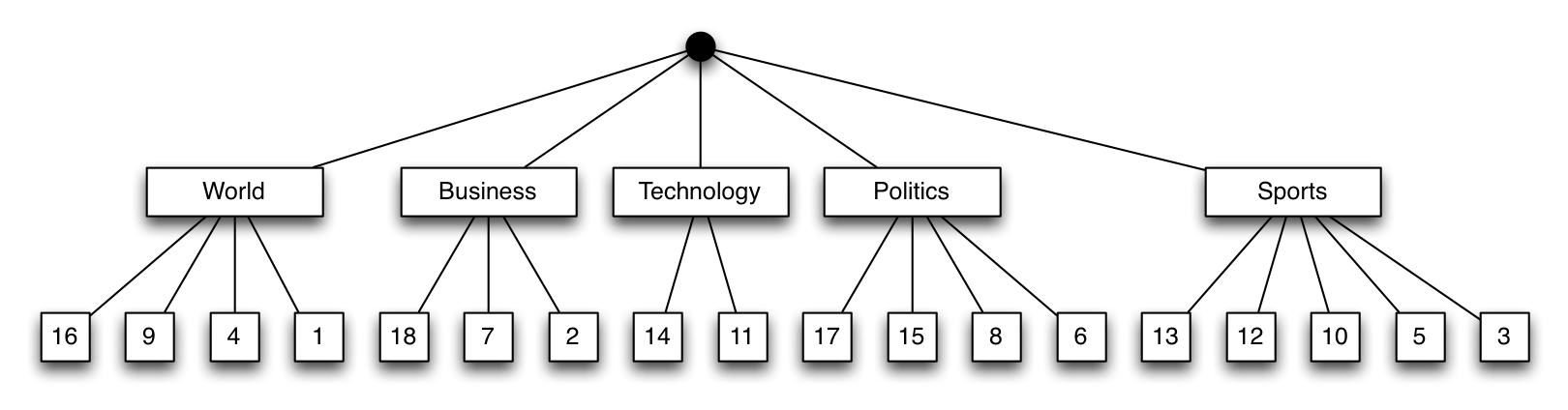
However, the documents are sorted by timestamp per individual $in branch, not globally. Therefore, if we request documents from several categories, the partially sorted lists would have to be merged. In theory, this could be done in linear time, by always picking the most recent document from each of the queues (often, this is referred to as a merge sort, but it is actually just the merge part in the merge sort algorithm). MongoDB does not currently do this (as of version 2.4.3), but this improvement is planned for the upcoming 2.6 release (SERVER-3310). Other optimizations are already in place, like limiting each of the branches to the total requested limit (SERVER-5063). For small limit values, the current implementation is still quite fast. But what if we want the top 100,000 documents from 10 different categories? MongoDB would have to sort up to 1 million documents in memory, then return the top 100,000. With a memory restriction of 32MB currently, this is often simply impossible and MongoDB will complain, telling you to use a different index or ask for less documents.
Index on {ts:-1, category:1}
The alternative is to use the reversed index, first on timestamp, descending, then on categories. The Index Tree Diagram would look something like the this:
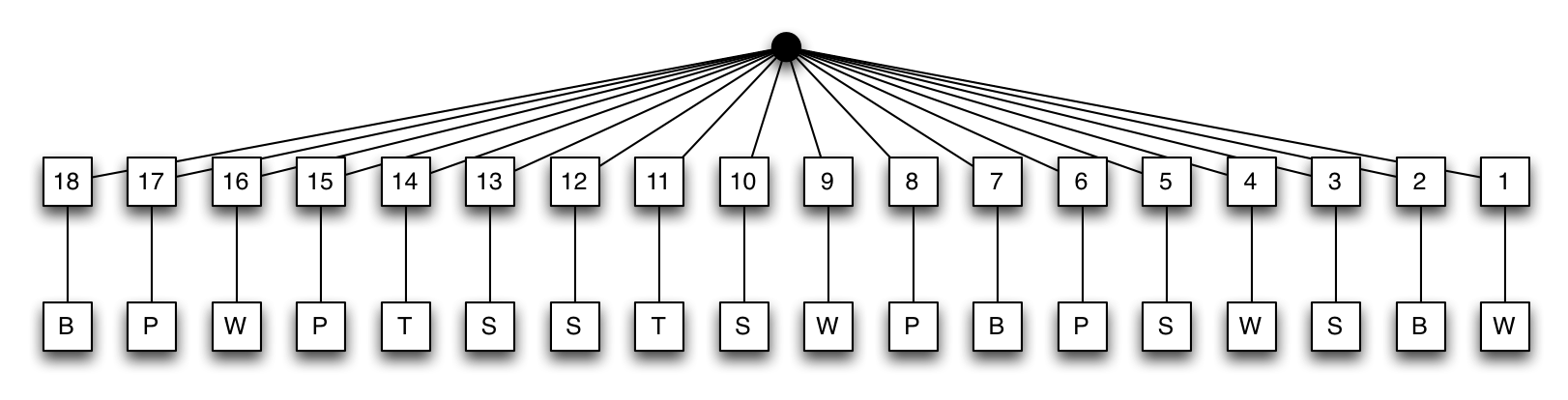
Note that we use simple integers as timestamp value here, but this could be any sortable value, like dates or epoch numbers.
Now the documents are sorted globally, so any query can be returned in sorted order without in-memory sorts. But finding the matching categories requires to scan each of the index entries. Because the timestamp fields are all distinct from each other, each entry only links to a single document, with a single category entry. To retrieve the most recent n documents, MongoDB scans the index entries from left to right, filtering out any document that doesn’t match the requested categories, until it has reached the limit. This scan is done in linear time, but how many documents need to be scanned? In the previous approach, we needed to look at C $\cdot$ L documents at most, where C is the number of categories, and L is the limit, but they needed to be sorted in memory. Here, it depends on the distribution of the data. In the worst case, there aren’t enough matching documents, so every single document in the collection needs to be inspected. Not only take these collection scans a long time, they also mess up the working set in memory, in case you have more data than available RAM.
Can we do better?
Remember that our initial requirement was less strict than what we attempted with the last two solutions. We didn’t ask for sorted results, just for the most recent ones. One way to achieve this is by sorting and limiting. But there’s another possibility, that avoids the expensive sort:
var total = db.documents.count();
var k = 10000;
var results = db.documents
.find({
category: {"$in": ["Business", "Politics", "Sports"]},
ts: {"$gt": total-k}})
.hint({category: 1, ts: -1})
Instead of sorting and limiting the results, we use a second query condition on the ts field. Here the timestamp has to be greater than k. Basically, we limit the number of documents before we match the categories, not after, as we did in the previous solutions. We also force the query to use the index on category first. How many documents will this query return? 10,000? Most likely not, unless the last 10,000 documents by chance all fall into the correct categories. That’s unlikely, and for another find on different categories certainly not the case. Let’s call the number of returned documents r, which is most likely not equal to n, the number of documents we wanted. How different r and n are depends on the distribution of documents over the categories, and on our choice of k, the document limit before we filter out the categories. The upside of this query is that it is very fast. Matching the categories is simply a matter of branching into each of the category btree children, and limiting the results means setting a lower bound on the range.
So while this query didn’t really fit the brief of returning the most recent n matching documents, at least it ran very fast :-)
Let’s recap: We have a fast way of checking the last k documents and filtering out the ones that match the categories. The query will return the most recent r matching documents, which may be different from the desired number of n documents returned:
- k number of documents to check for category match
- r number of matching documents returned after inspecting k documents: r ≤ k
- n number of desired documents matching
We’d like to change the query so that r is closer to, ideally identical to, n. Given a fixed distribution of data over the categories, there is only one variable that we can adjust, and that is k. Let’s say we want to return the most recent n=5 documents, we queried with k=5 documents (the lower bound), and got r=3 documents back. That’s not enough, so we repeat the query with a higher k=6. This time, we get 4 documents back, which is closer to n but doesn’t quite reach it yet. A third query with k=7 does the trick, and we now have the most recent 5 documents, without relying on a .sort() in the query.
The graphic below shows this example for k=5, 6, 7. Each time we push the lower bound bracket (calculated as total-k) a little further to the right on each of the category branches, until the final results returns the desired number of documents.
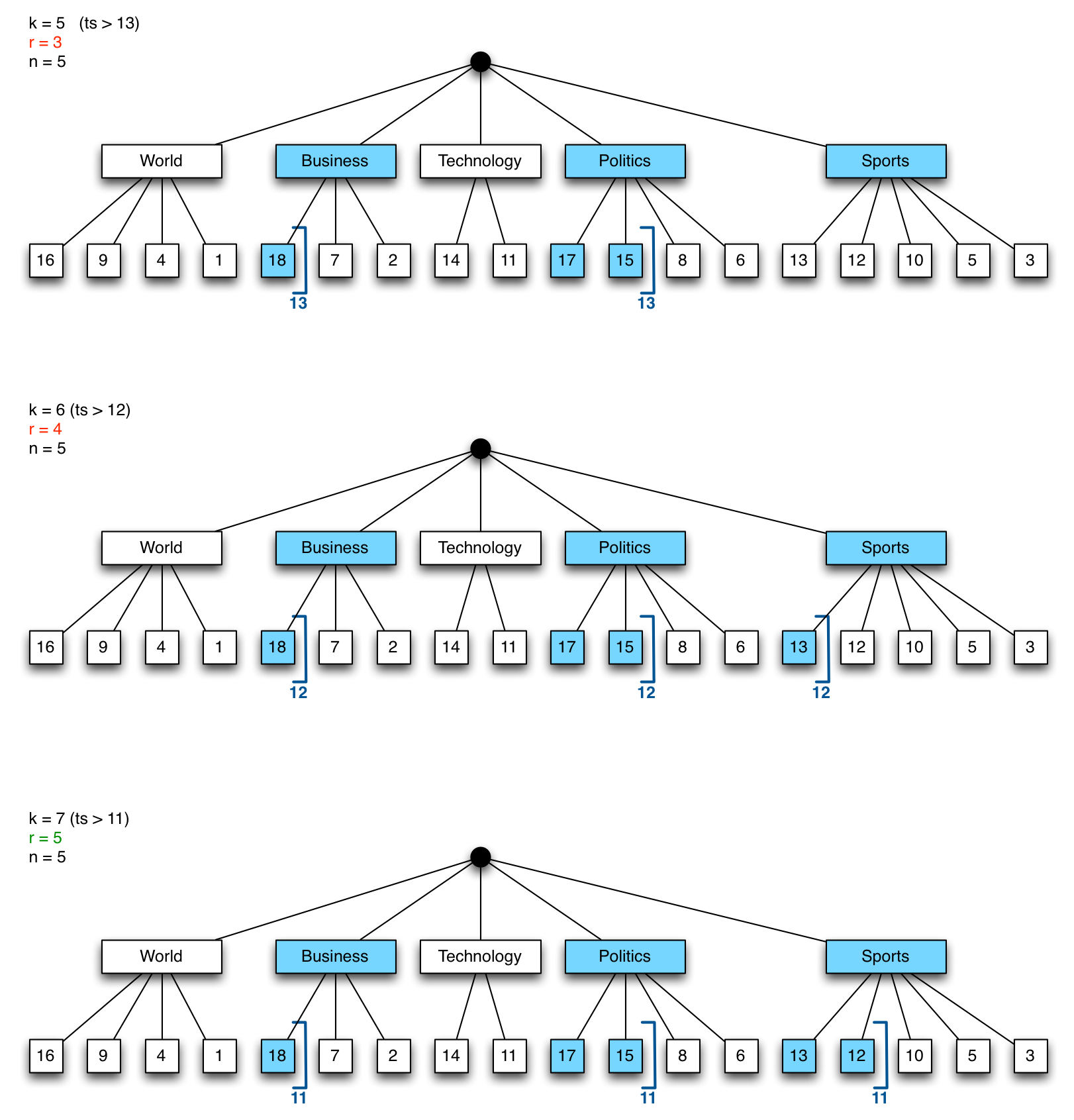
With 3 fast queries (4 if we count the initial count), we have now found the most recent 5 documents that match the given categories without using a sort or having to scan through a lot of documents.
Optimizing the Iterative Algorithm
There are a few more optimizations that we can make use of.
In above example, we linearly increased k from 5 to 6 to 7, but we don’t have to search every single k. Instead, we can use a binary search on k until we get to the correct number of matching documents, which only requires log(n) steps in the worst case.
The second optimization is more of a suggestion to relax the conditions even a little further. Perhaps you don’t really need exactly n most recent documents. Then you can make use of the fact, that with binary search, you can trade some precision for a bit more performance. If your use case allows a small error margin on n, you can iterate until the number of returned documents lies within the error bounds. This can have a dramatic effect on performance, as a lot of iteration steps would be used to get exactly to n matching documents. The algorithm below allows to specify a min and max value, and it will stop iterations when the number of matching documents lies within that range. Even an error margin of 5% can reduce the number of necessary iterations significantly. You can still specify a .limit(n) on the cursor, to get at most n documents. This allows for flexible use cases, for example:
Return exactly 100,000 documents, where these documents are at least in the most recent 105,000 documents (5% error margin).
For parallel queue processing, this may be an acceptable requirement, which can be answered much quicker than the sorted queries.
Results
In this test I used 5 million documents separated into 100 categories, which isn’t that much when you think about them as actors for a movie database, or product categories for an online shop for example.
I’ve ran both the sorted and the iterative version for different numbers of n: 100, 1000, 10000, 25000, 50000, 75000, 100000. The error margin for r was 10% (so anything between n and 1.1 $\cdot$ n was acceptable). Here are the results:
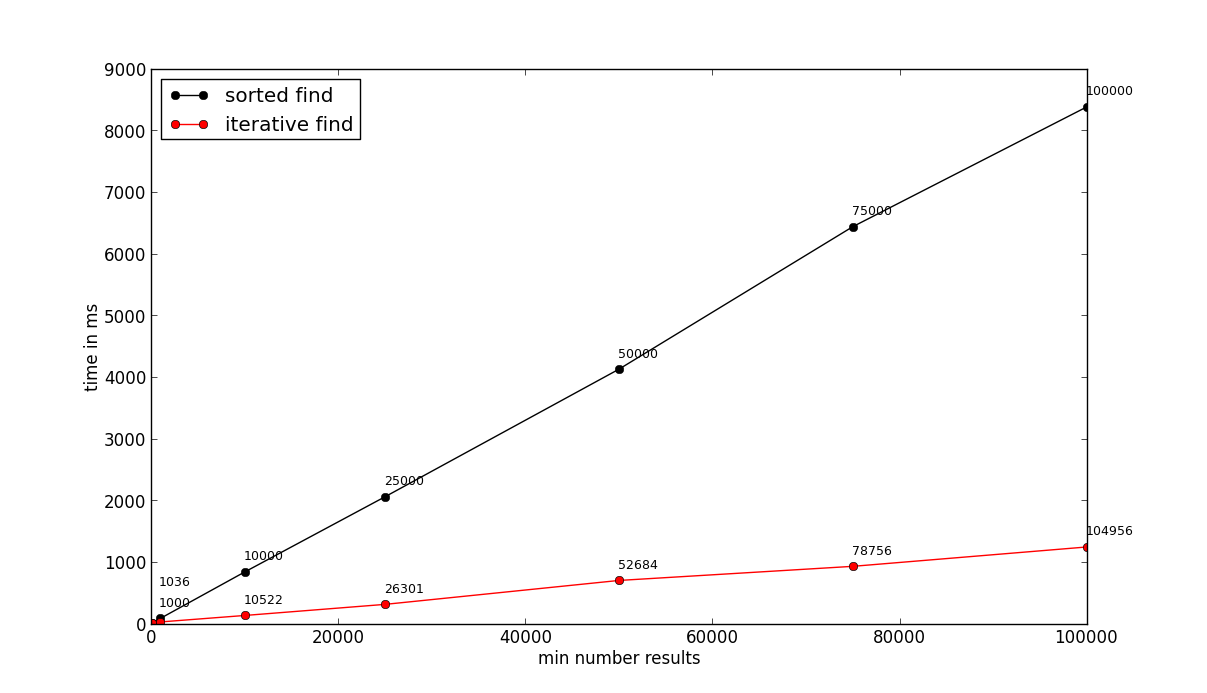
The x-axis is the number of most recent documents n to retrieve, the y-axis shows how long each query took in milliseconds. The numbers above each measurement point show how many documents (r) were actually retrieved. For 100,000 documents, the sorted query was roughly 8x slower than the iterative one. These results depend on your data distribution and the number of categories though. With less categories, the difference may not be as big. As always, test your queries in a staging/QA environment.
Implementation
Here is a javascript function that finds the n most recent documents matching the categories given in query, where n will be between min and max. query needs to be of the form: {cat: {$in: [1, 55, 88]}}
function findRecent(collection, query, min, max) {
var total = db[collection].count();
var step, marker, cursor, c, last_marker, qc;
step = min;
marker = total;
c = 0;
while (c < min) {
last_marker = marker;
marker = marker - step;
query['ts'] = {'$gt': marker};
cursor = db[collection].find(query).hint({cat:1, ts:-1});
c = cursor.count();
step = step*2;
}
if (c < max) {
return cursor;
}
step = (last_marker - marker) / 2;
marker = marker + step;
while (true) {
query['ts'] = {'$gt': marker};
cursor = db[collection].find(query).hint({cat:1, ts:-1});
c = cursor.count();
step = step/2;
if (c > max) {
marker = marker + step;
} else if (c < min) {
marker = marker - step;
} else {
return cursor;
}
}
}
And if you want to reproduce these results, I used this little Python script to fill the database (using numbers 0–99 for categories):
from pymongo import MongoClient, ASCENDING, DESCENDING
from random import choice
categories = range(100)
mc = MongoClient("localhost:27017")
db = mc.test
db.docs.drop()
interval = 1000
docs = []
for i in xrange(5000000):
doc = {"cat": choice(categories), "ts": i}
docs.append(doc)
if i % interval == interval-1:
print i
db.docs.insert(docs, w=0)
docs = []